앞에서 mnist 숫자 분류 문제를 보았다. 데이터와 정답이 있고, 그것을 학습하여 정답을 맞추는 문제였었다.
그런데 현실 세계에서는 정답이 없는 경우가 더 많다.
정답이 새로 생기는 경우도 있다.
예를 들어 자동차를 종류별로 분류한다고 하자. 승용차, 승합차, 버스, 트럭 등등...
자동차 사진을 모으고, 각 사진마다 레이블을 붙여서 정답 데이터를 만들었다.
그렇게 만든 데이터로 학습시킨 모델을 실제 사용해보니...
그 사이에 어느 분류에도 속하지 않은 3륜 자동차가 새로 나왔다. 이런 경우는 어떻게 해야 하나?
본 예제는 이런 경우에 대응하는 한 방법에 대한 예제이다.
mnist 데이터 중에 1~7번 까지만 학습에 사용하고, 0,8,9는 학습에 사용하지 않는다. 즉, 0,8,9는 학습되지 않은 새로운 데이터가 된다. 이런 데이터가 섞여 있는 경우, 어떻게 처리하는 것이 좋을까?
학습된 모델은 predict를 수행하면서 해당 predict에 대한 신뢰도를 얻을 수 있다. 이 신뢰도값을 이용해서 일정수준 이하의 신뢰도를 갖으면 unknown class로 분류하려고 한다.
일단 코드를 보자.
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms
from torch.utils.data import DataLoader, Subset, random_split
import numpy as np
# 1. 데이터셋 준비 (1~7만 학습)
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])
full_dataset = datasets.MNIST(root='./data', train=True, download=True, transform=transform)
# 3. train/test 비율 설정 (8:2)
train_size = int(0.8 * len(full_dataset)) # 48000
test_size = len(full_dataset) - train_size # 12000
train_dataset, test_dataset = random_split(full_dataset, [train_size, test_size])
# 1~7 숫자만 학습 데이터로 사용
train_indices = [i for i, (img, label) in enumerate(train_dataset) if 1 <= label <= 7]
train_subset = Subset(train_dataset, train_indices)
# 2. 모델 정의
class SimpleNet(nn.Module):
def __init__(self):
super(SimpleNet, self).__init__()
self.fc1 = nn.Linear(28*28, 128)
self.fc2 = nn.Linear(128, 64)
self.fc3 = nn.Linear(64, 7) # 1~7 => 7개 클래스
def forward(self, x):
x = x.view(-1, 28*28)
x = torch.relu(self.fc1(x))
x = torch.relu(self.fc2(x))
x = self.fc3(x)
return x
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = SimpleNet().to(device)
# 3. 학습 설정
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
train_loader = DataLoader(train_subset, batch_size=64, shuffle=True)
# 4. 학습
for epoch in range(5):
model.train()
running_loss = 0.0
for images, labels in train_loader:
images, labels = images.to(device), labels.to(device)
labels = labels - 1 # 1~7 → 0~6으로 맞춤
optimizer.zero_grad()
outputs = model(images)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
running_loss += loss.item()
print(f"Epoch {epoch+1}, Loss: {running_loss / len(train_loader)}")
# 5. 테스트 (unknown detection)
model.eval()
test_loader = DataLoader(test_dataset, batch_size=1, shuffle=False)
threshold = 0.8 # 이 확률보다 낮으면 unknown으로 판단
correct, total, unknown_count = 0, 0, 0
with torch.no_grad():
for images, labels in test_loader:
images = images.to(device)
labels = labels.numpy()[0]
outputs = model(images)
probs = torch.softmax(outputs, dim=1)
max_prob, predicted = torch.max(probs, 1)
if 1 <= labels <= 7:
total += 1
if max_prob.item() >= threshold and predicted.item() == (labels-1):
correct += 1
elif labels in [0,8,9]:
if max_prob.item() < threshold:
unknown_count += 1
print(f"\nTest Accuracy (1~7): {100*correct/total:.2f}%")
print(f"Detected unknowns (0,8,9): {unknown_count}개")
기본적인 흐름은 simple mnist 예제와 동일하다.
데이터를 가져오고, 모델을 정의하고, 학습 관련 설정을 수행하고, 실제로 학습을 진행하고, 마지막으로 테스트를 수행한다.
여기서 다른 점은 아래 코드 부분이다.
outputs = model(images)
probs = torch.softmax(outputs, dim=1)
max_prob, predicted = torch.max(probs, 1)
1) 학습된 모델에 images를 넣고, predict 결과로 outputs를 얻었다.
2) outputs 결과에 대해 softmax를 수행하여 0~1사이의 확률값으로 변환한다.
3) 확률값 중 가장 높은 값(max_prob)과 그것의 라벨(predicted)를 얻었다.
그리고 아래의 나머지 코드 부분에서 max_prob 값이 미리 설정한 threashold 값(0.8)보다 낮으면 unknown class로 분류한 것으로 간주하였다.
if 1 <= labels <= 7:
total += 1
if max_prob.item() >= threshold and predicted.item() == (labels-1):
correct += 1
elif labels in [0,8,9]:
if max_prob.item() < threshold:
unknown_count += 1
위의 코드를 실제 돌려보면 아래와 같은 결과를 얻을 수 있다.
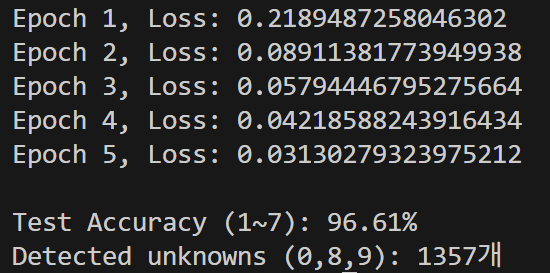
한번 unknown 으로 검지된 것을 자세히 보도록 하자.
그리고 0,8,9 전체 중에 얼마나 unknown으로 검지했는지도 확인해보자.
5.테스트 부분만 아래 코드로 변경해주면 된다.
# 5. 테스트 및 unknown detection
model.eval()
test_loader = DataLoader(test_dataset, batch_size=1, shuffle=False)
threshold = 0.8 # 이 확률보다 낮으면 unknown으로 판단
correct, total = 0, 0
unknown_correct, unknown_total = 0, 0
unknown_samples = [] # unknown으로 분류된 샘플 저장용
with torch.no_grad():
for images, labels in test_loader:
images = images.to(device)
labels_np = labels.numpy()[0]
outputs = model(images)
probs = torch.softmax(outputs, dim=1)
max_prob, predicted = torch.max(probs, 1)
if 1 <= labels_np <= 7:
total += 1
if max_prob.item() >= threshold and predicted.item() == (labels_np-1):
correct += 1
elif labels_np in [0,8,9]:
unknown_total += 1
if max_prob.item() < threshold:
unknown_correct += 1
if len(unknown_samples) < 5: # 5개까지만 저장
unknown_samples.append((
images.cpu(),
labels_np,
predicted.item()+1, # 모델 예측값 (1~7로 맞춰줌)
max_prob.item()
))
# 6. 결과 출력
if total > 0:
print(f"\n[1~7 숫자 정확도] : {100 * correct / total:.2f}%")
else:
print("\n[1~7 숫자 데이터 없음]")
if unknown_total > 0:
print(f"[0,8,9 unknown 정확도] : {100 * unknown_correct / unknown_total:.2f}% (총 {unknown_total}개 중 {unknown_correct}개)")
else:
print("\n[unknown 데이터 없음]")
# 7. unknown 샘플 시각화
if unknown_samples:
fig, axes = plt.subplots(1, len(unknown_samples), figsize=(14, 3))
fig.suptitle("Detected Unknown Samples (0,8,9)", fontsize=15)
for idx, (img_tensor, true_label, pred_label, prob) in enumerate(unknown_samples):
ax = axes[idx]
ax.imshow(img_tensor.squeeze(), cmap='gray')
ax.axis('off')
ax.set_title(f"True: {true_label}\nPred: {pred_label}\nProb: {prob:.2f}")
plt.tight_layout()
plt.show()
else:
print("\nunknown으로 분류된 샘플이 없습니다.")
그러면 아래와 같은 결과를 얻을 수 있다.

unknown으로 분류된 샘플들을 출력해보면 아래와 같다.

흠... 학습하지 않은 상태에서 모르는 것을 모르겠다고 분류한 것만 해도 괜찮다고 해야할지... 약간 애매하지만..
확실히 향후 개선의 가능성은 있어보인다.
오늘은 여기까지!!
'Deep Learning' 카테고리의 다른 글
| Gymnasium (강화학습 라이브러리) (0) | 2025.05.20 |
|---|---|
| Imitation Learning - gymnasium (0) | 2025.05.19 |
| PyTorch with GPU 설치하기 (0) | 2025.05.16 |
| Simple Imitation Learning (0) | 2025.05.15 |
| Simple Object Detection with DETR (1) | 2025.05.13 |


